Scrapy-ImagePipelines
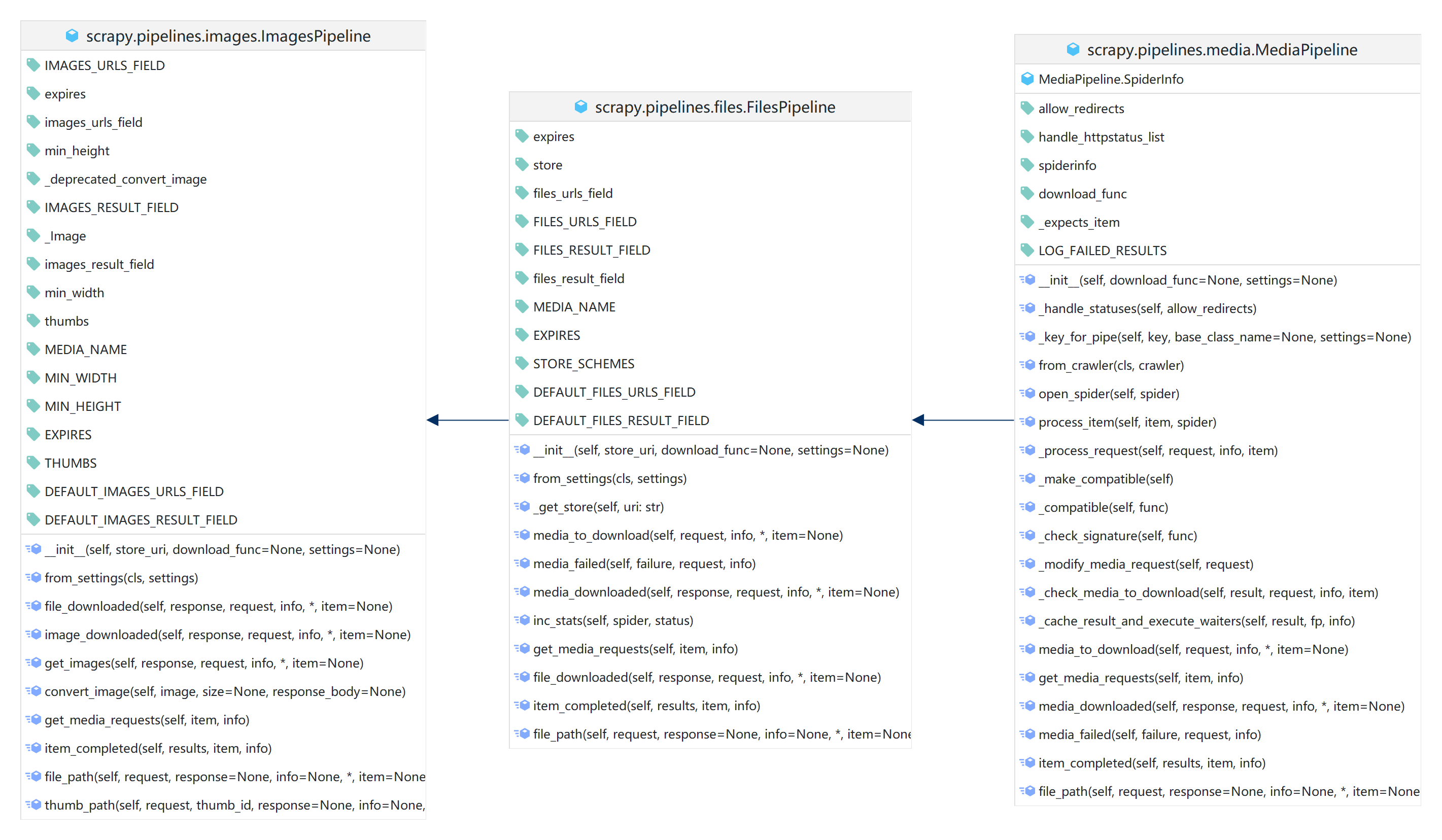
类继承关系如下
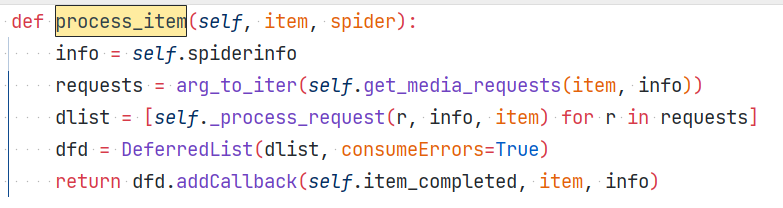
pipeline执行时先调用父类的process_item(self, item, spider)
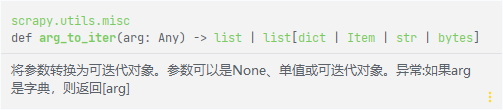
调用get_media_requests(item, info)方法, get_media_requests()方法, 用于生成一个scrapy.Request, 将返回结果转为requests列表,
将requests中的每一项交给self._process_request处理,
将处理的结果转为twisted.internet.defer.DeferredList列表
DeferredList的函数文档如下

向该DeferredList添加一个回调方法self.item_completed, 并将item, info信息传递过去, 其中item为传入pipeline的item, info为spiderinfo也就是爬虫信息, 返回值就是添加的回调方法的返回值
每一个对象在通过self.item_completed处理过后, 返回item, 此时这个pipeline执行结束
这其中关键部分在于self._process_request
self._process_request执行过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| def _process_request(self, request, info, item):
fp = self._fingerprinter.fingerprint(request)
if not request.callback or request.callback is NO_CALLBACK:
cb = _DUMMY_CALLBACK
else:
cb = request.callback
eb = request.errback
request.callback = NO_CALLBACK
request.errback = None
if fp in info.downloaded:
return defer_result(info.downloaded[fp]).addCallbacks(cb, eb)
wad = Deferred().addCallbacks(cb, eb)
info.waiting[fp].append(wad)
if fp in info.downloading:
return wad
info.downloading.add(fp)
dfd = mustbe_deferred(self.media_to_download, request, info, item=item)
dfd.addCallback(self._check_media_to_download, request, info, item=item)
dfd.addBoth(self._cache_result_and_execute_waiters, fp, info)
dfd.addErrback(
lambda f: logger.error(
f.value, exc_info=failure_to_exc_info(f), extra={"spider": info.spider}
)
)
return dfd.addBoth(lambda _: wad)
|
方法内通过info.downloaded判断文件下载状态, 第一次判断后如果未下载完, 生成一个wad对象, 将其添加到等待队列中, 直到完成下载
下载后
- 调用
self.media_to_download方法用于存储介质中文件信息的读取, 以及文件是否过期的过滤
- 调用
self._check_media_to_download方法用于
在media_to_download方法中,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| def media_to_download(self, request, info, *, item=None):
def _onsuccess(result):
if not result:
return
last_modified = result.get("last_modified", None)
if not last_modified:
return
age_seconds = time.time() - last_modified
age_days = age_seconds / 60 / 60 / 24
if age_days > self.expires:
return
referer = referer_str(request)
logger.debug(
"File (uptodate): Downloaded %(medianame)s from %(request)s "
"referred in <%(referer)s>",
{"medianame": self.MEDIA_NAME, "request": request, "referer": referer},
extra={"spider": info.spider},
)
self.inc_stats(info.spider, "uptodate")
checksum = result.get("checksum", None)
return {
"url": request.url,
"path": path,
"checksum": checksum,
"status": "uptodate",
}
path = self.file_path(request, info=info, item=item)
dfd = defer.maybeDeferred(self.store.stat_file, path, info)
dfd.addCallbacks(_onsuccess, lambda _: None)
dfd.addErrback(
lambda f: logger.error(
self.__class__.__name__ + ".store.stat_file",
exc_info=failure_to_exc_info(f),
extra={"spider": info.spider},
)
)
return dfd
|
先调用self.file_path方法获得存储的路径(本地路径或其他对象存储服务路径, 可以通过重写此方法实现自定义路径)
存储方案包括:
1
2
3
4
5
6
7
| STORE_SCHEMES = {
"": FSFilesStore,
"file": FSFilesStore,
"s3": S3FilesStore,
"gs": GCSFilesStore,
"ftp": FTPFilesStore,
}
|
将使用的存储方案对应的stat_file方法, 刚刚获取到的文件存储路径和info添加到回调信息中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def stat_file(self, path, info):
def _onsuccess(boto_key):
checksum = boto_key["ETag"].strip('"')
last_modified = boto_key["LastModified"]
modified_stamp = time.mktime(last_modified.timetuple())
return {"checksum": checksum, "last_modified": modified_stamp}
return self._get_boto_key(path).addCallback(_onsuccess)
def _get_boto_key(self, path):
key_name = f"{self.prefix}{path}"
return threads.deferToThread(
self.s3_client.head_object, Bucket=self.bucket, Key=key_name
)
|
这一回调主要目的是通过存储方案中对应的方法获取文件是否存在, 以及对已存在文件信息的获取
整个过程可以算作异步处理的
最后返回获取到的文件{"checksum", "last_modified"}信息
将media_to_download的_onsuccess方法添加为回调方法用于处理上一行代码获取到的文件信息,
_onsuccess方法中通过age_seconds = time.time() - last_modified判断本地文件存在时间
然后跟self.expires进行比较用户判断是否需要将文件更新存储
这里的self.expires默认为90天, 优先从settings.IMAGES_EXPIRES读取,
最后方法返回dfd, _onsuccess方法的返回值, 即一些信息{"url", "path", "checksum", "status"}至此, media_to_download方法调用结束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| def _check_media_to_download(self, result, request, info, item):
if result is not None:
return result
if self.download_func:
dfd = mustbe_deferred(self.download_func, request, info.spider)
dfd.addCallbacks(
callback=self.media_downloaded,
callbackArgs=(request, info),
callbackKeywords={"item": item},
errback=self.media_failed,
errbackArgs=(request, info),
)
else:
self._modify_media_request(request)
dfd = self.crawler.engine.download(request)
dfd.addCallbacks(
callback=self.media_downloaded,
callbackArgs=(request, info),
callbackKeywords={"item": item},
errback=self.media_failed,
errbackArgs=(request, info),
)
return dfd
|
result参数存储的是media_to_download方法的返回值

一共有三种情况会返回None
方法主要内容就是调用media_downloaded方法进行图片url的下载
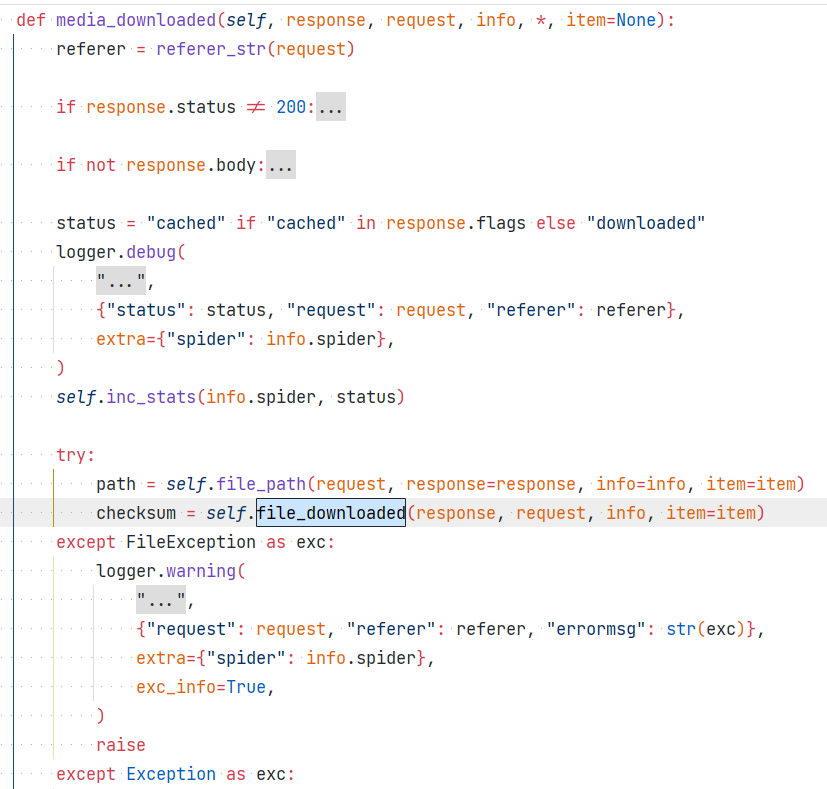
方法内部调用self.file_downloaded, 这个根据使用的存储方案选取相应的文件上传实现, (这里选取S3FilesStore即对象存储服务)下面是重写后的file_downloaded用来调用image_downloaded
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| def file_downloaded(self, response, request, info, *, item=None):
return self.image_downloaded(response, request, info, item=item)
def image_downloaded(self, response, request, info, *, item=None):
checksum = None
for path, image, buf in self.get_images(response, request, info, item=item):
if checksum is None:
buf.seek(0)
checksum = md5sum(buf)
width, height = image.size
self.store.persist_file(
path,
buf,
info,
meta={"width": width, "height": height},
headers={"Content-Type": "image/jpeg"},
)
return checksum
|
处理后返回的checksum通过media_downloaded方法返回
